

Kako dobiti riječ tekst sa slike

- 2379
- 434
- Donald Willms
Prije nego što je svaki korisnik računala barem jednom bilo potrebno dobiti tekstualne podatke sa slika. Radeći u programima zapošljavanja, ponekad morate preispitivati tekst na slici rastera ili vektora. Ovaj dugi postupak može se smanjiti ako znate kako izvući tekst u riječ sa slike.
Da biste pretvorili tekst u sliku u Wordov dokument - slijedite upute u nastavku
Izlaz
Obično je postupak prepoznavanja sa slikom prilično naporan. Morat će ručno obaviti glavni posao u njemu, ali konačni rezultat uštedjet će ukupno provedeno vrijeme. To je neophodno kada je na raspolaganju samo elektronička slika dokumenta ili stranice knjige, od kojih trebate izvući tekst.
Umjesto vlastitih podataka o ponovnom tiskanju, možete koristiti specijalizirane programe i usluge koji automatiziraju ovaj rad. Omogućuju vam prepoznavanje teksta koristeći slike najpopularnijih formata, uključujući JPG, GIF i PNG.
Redoslijed rada
Ako su podaci u tiskanom dokumentu, morat će unaprijed napraviti sliku iz nje. Ovo će zahtijevati skener. Također je potrebno ako tekst na slici ima lošu rezoluciju ili je zamagljen. "Nativni" pokretači i programi koji će prevesti sve u visokoj kvaliteti trebaju biti pričvršćeni na skener. Na rezultat utječe ne samo jasnoća slova, već i njihov "čak" položaj, kao i nedostatak uplitanja.

Ako trebate dobiti tekst iz papirnog medija, potreban vam je skener
Ako imate skener, možete doći s kamerom. U ovom slučaju morate pravilno postaviti svjetlo. Sljedeća faza zahtijeva korištenje posebnih programa koji će vam omogućiti da izravno prepoznate tekst s JPG -om. Među takvim programima Abbyy FineReader zauzima posebno mjesto, koje se smatra lider na tržištu. Plaćena je, ali njegova kvaliteta odgovara troškovima.
Značajke postupka
U softverskoj funkcionalnosti postoje mnoge funkcije za rad s većinom fontova. Među naprednim mogućnostima postoji mogućnost prepoznavanja rukom pisanog teksta riječi iz JPG -a. Ima mnogo prednosti:
- Izbor kvalitete. Sam korisnik može zaustaviti preferiranu kvalitetu za skeniranje. Bolje je odabrati najmanje 300 dpi, tako da program utječe na čak i male dijelove za obradu i može raditi s malim fontovima.
- Boja. Potrebno je kada na slici postoje stolovi ili drugi simboli. U ostalim opcijama poželjno je odabrati crno -bijeli način rada, koji će ukloniti pomak raspona boja iz slova, čineći ih čistijim. Način boje prikladan je za svijetle slike, gdje je važno prenijeti boju teksta.
- fotografija. Ako slika napravi slika, program će povećati prioritet skeniranja. Tekst također možete izravno fotografirati s Abbyy FineReader da biste ga prepoznali u JPG -u. Istina, ovo će uvelike pogoršati kvalitetu, zbog čega će konačni rezultat imati mnogo pogrešaka.
Među sličnim programima postoje i besplatne usluge. Među njima je također istaknuo i Google Drive, koji je dostupan izravno u pregledniku. Rad s OCR pretvorbom ima prosječnu kvalitetu, stoga je prikladan za one čija slika ima veliko širenje i jasne fontove. I2OCR usluga nudi slične usluge, samo se slike mogu preuzeti s URL veze. Imaju više amaterskog formata, dakle, ne smatraju se profesionalnom uporabom.
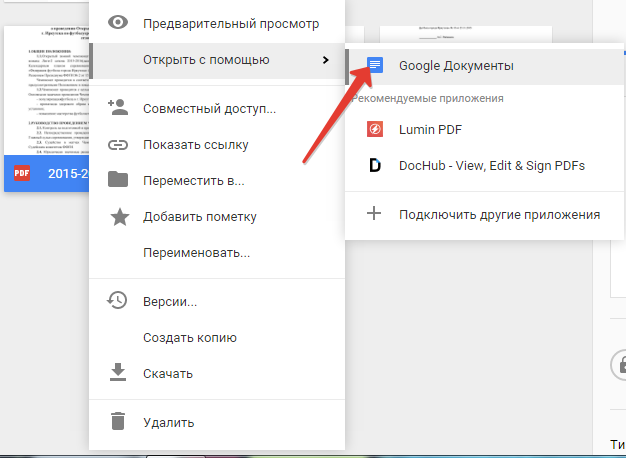
Otvorivši sliku putem Google dokumenata, dobit ćete dokument s već prepoznatim tekstom
Dobiti rezultat
Nakon početka skeniranja, obično je potrebno nekoliko minuta da se rezultat. Ovaj pokazatelj ovisi o složenosti i količini tijela. Nakon početka rada, programi u automatskom načinu dodijelit će područja za provjeru i pretvoriti ih. Nakon završetka postupka možete ponovno prepoznati podatke o JPG -u ili se usredotočiti na određena područja dokumenta.
Gotovi rezultat izvozi se u datoteku riječi. Rezultirajući tekst može se uređivati prilikom promatranja pogrešaka ili nastaviti dalje raditi s njim. Prepoznati tekst iz JPG slika nije teško ako je slika ispravno pripremljena. Ovaj postupak može značajno uštedjeti vrijeme, za razliku od ručnog ponovnog tiskanja informacija.
Budući da rad s prepoznavanjem teksta sa slike zahtijeva izvor visoke kvalitete, u početku morate pronaći sliku s visokom rezolucijom. To će ubrzati proces obrade podataka, a također će smanjiti ukupnu količinu pogrešaka.